
AI音声合成技術の進化により、誰でも簡単に自然な音声を生成できる時代になりました。しかし、その一方で「この音声は本当に本人が話したものなのか?」「AIが生成した音声ではないのか?」という疑問が常につきまといます。
この問題に対して、Resemble AI が開発したオープンソースTTS(Text-to-Speech)エンジン「Chatterbox 」は、ユニークな解決策を提示しています。それがPerth Watermarkerという、人間には知覚できないニューラルウォーターマーク技術です。
本記事では、まだ日本ではほとんど知られていないChatterboxの全貌と、その核心技術であるPerth Watermarkerの仕組みを深掘りしていきます。
Chatterboxとは:3つのモデルファミリー
ChatterboxはResemble AI が公開した、オープンソース音声合成エンジンです。GitHub上では15,900スター以上を獲得していますが、日本語圏での認知度はまだ低く、解説記事もZenn/Qiitaに2件程度しか存在しません。
Resemble AIとは
Resemble AIは、音声AI技術に特化したカナダのスタートアップ企業です。主力製品は商用の音声クローニングサービスですが、研究開発の成果をオープンソースとして公開する方針を取っています。Chatterboxはその代表例です。
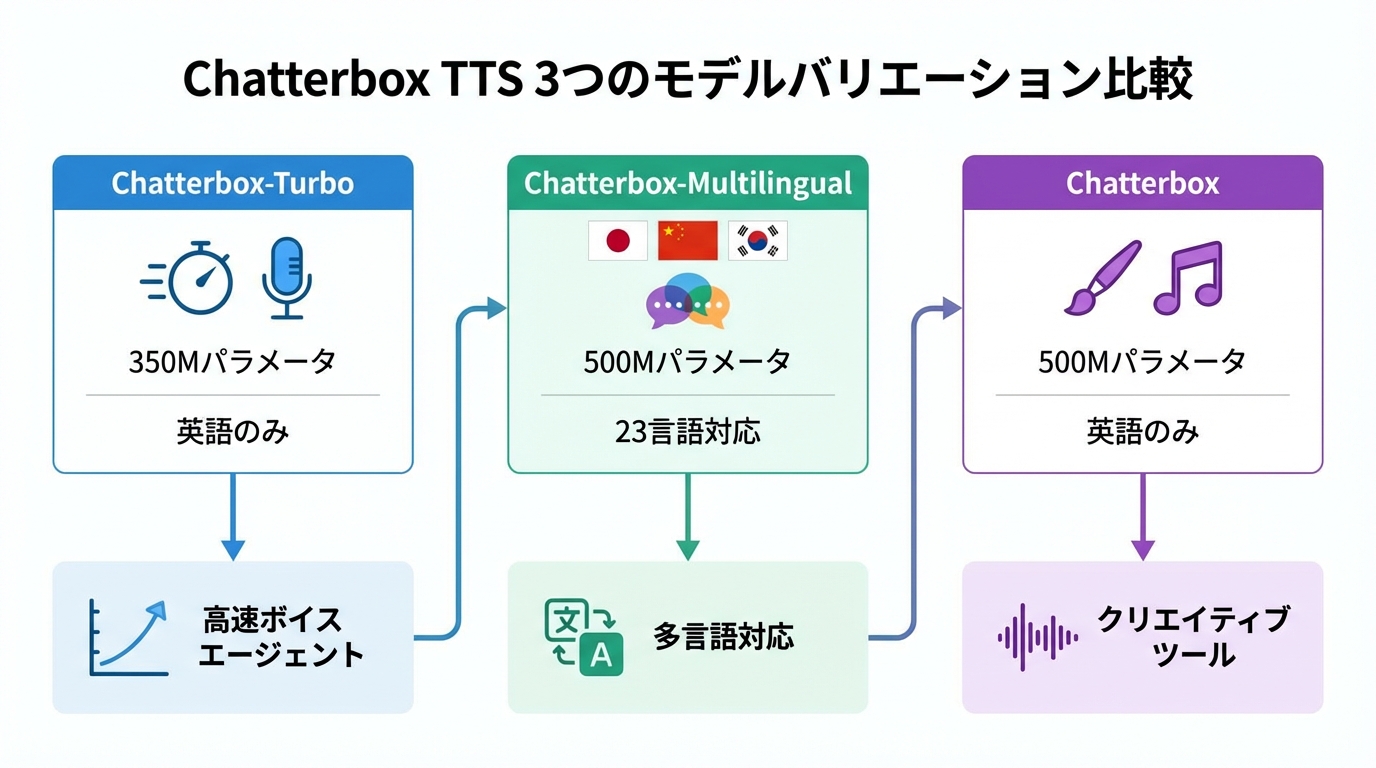
3つのモデルバリエーション
Chatterboxは現在、3つのモデルファミリーを提供しています:
| モデル | パラメータ数 | 対応言語 | 主な特徴 | 用途 |
|---|---|---|---|---|
| Chatterbox-Turbo | 350M | 英語のみ | パラリンギスティックタグ([laugh]等)、低VRAM | ボイスエージェント、プロダクション |
| Chatterbox-Multilingual | 500M | 23言語以上 | ゼロショット音声クローニング | 多言語アプリ、ローカライゼーション |
| Chatterbox | 500M | 英語のみ | CFG・Exaggeration調整 | 汎用TTS、クリエイティブ用途 |
重要: 最新のTurboモデル(2025年12月リリース)は、1ステップのmelデコーダーを採用し、以前のモデルより大幅に高速化されています。
Chatterbox-Multilingualの対応言語
アラビア語(ar)・デンマーク語(da)・ドイツ語(de)・ギリシャ語(el)・英語(en)・スペイン語(es)・フィンランド語(fi)・フランス語(fr)・ヘブライ語(he)・ヒンディー語(hi)・イタリア語(it)・日本語(ja)・韓国語(ko)・マレー語(ms)・オランダ語(nl)・ノルウェー語(no)・ポーランド語(pl)・ポルトガル語(pt)・ロシア語(ru)・スウェーデン語(sv)・スワヒリ語(sw)・トルコ語(tr)・中国語(zh)
従来のTTS市場とChatterboxの位置づけ
音声合成市場は大きく3つに分かれています:
1. 商用クローズドサービス
- ElevenLabs :月額$5〜$330、最高品質だが高コスト
- Google Cloud TTS :従量課金、品質は中程度
- Amazon Polly :AWSエコシステム向け
2. オープンソース(日本語特化)
- VOICEVOX :日本語最強、キャラクター音声
- Style-Bert-VITS2 :感情表現が豊富
3. オープンソース(英語・多言語)
- Coqui TTS :2024年アーカイブ済み
- Chatterbox:透かし技術内蔵で差別化
Chatterboxは「ElevenLabs級の品質をオープンソースで」という野心的な目標を掲げていますが、最大の特徴はすべての生成音声に自動的に電子透かしが埋め込まれるという点です。
技術仕様と特徴
Chatterbox-Turbo(最新モデル)の基本スペック:
| 項目 | 詳細 |
|---|---|
| ライセンス | MITライセンス(商用利用可) |
| 実装言語 | Python 3.11推奨 |
| モデル構造 | 350Mパラメータ、1-step mel decoder |
| 対応言語 | 英語のみ(Multilingualは23言語対応) |
| 音声品質 | 24kHz(商用サービス相当) |
| GPU要件 | VRAM 4GB以上推奨(CPUでも動作可能) |
| 透かし技術 | Perth Watermarker(必須・無効化不可) |
なぜ今Chatterboxなのか
Chatterboxが注目される理由は3つあります:
1. ElevenLabsの代替としてのコスト削減
ElevenLabsは高品質ですが、年間コストが大きな問題でした:
- Free tier: 月10,000文字(すぐ枯渇)
- Starter: $5/月 → 年間$60
- Creator: $22/月 → 年間$264
- Pro: $99/月 → 年間$1,188
- Scale: $330/月 → 年間$3,960
Chatterboxなら初期投資ゼロ、サーバー費用のみで無制限に使えます。
2. セルフホスト時代の到来
プライバシー意識の高まりにより、音声データを外部サービスに送信したくない企業が増加中。Chatterboxはオンプレミスやプライベートクラウドで完結できます。
3. AI悪用対策への社会的要請
詐欺電話やディープフェイク音声の被害が急増しており、「AI生成音声の証明可能性」が法的・技術的課題として浮上。Chatterboxはこの問題に正面から取り組んでいます。
現時点での制約
一方で、以下の制約もあります:
- Turboモデルは英語のみ(Multilingualモデルで日本語対応済み)
- ドキュメントが簡素(公式READMEが主な情報源)
- コミュニティが小規模(GitHub Issues/Discussionsが活発ではない)
日本語で高品質なTTSが必要な場合は、Chatterbox-Multilingualモデルを使用できます。
Perth Watermarker:人間には聞こえない"指紋"
Chatterboxの最大の特徴である透かし技術について掘り下げます。
なぜ透かしが必要なのか
AI音声技術の悪用例が急増しています:
実際の被害事例
詐欺電話(2024年香港)
- CFOの声を偽装して経理担当者に送金指示
- 被害額:2,500万ドル(約37億円)
政治的フェイクニュース(2024年米国)
- 大統領候補の偽音声で虚偽発言を拡散
- 選挙運動に影響
著作権侵害(継続的問題)
- 声優やナレーターの声を無断複製
- 本人の仕事を奪う事態に
従来のデジタル署名やメタデータでは、以下の問題がありました:
- 音声編集で簡単に削除される
- ファイル形式変換で消失する
- そもそも付与されていない場合が多い
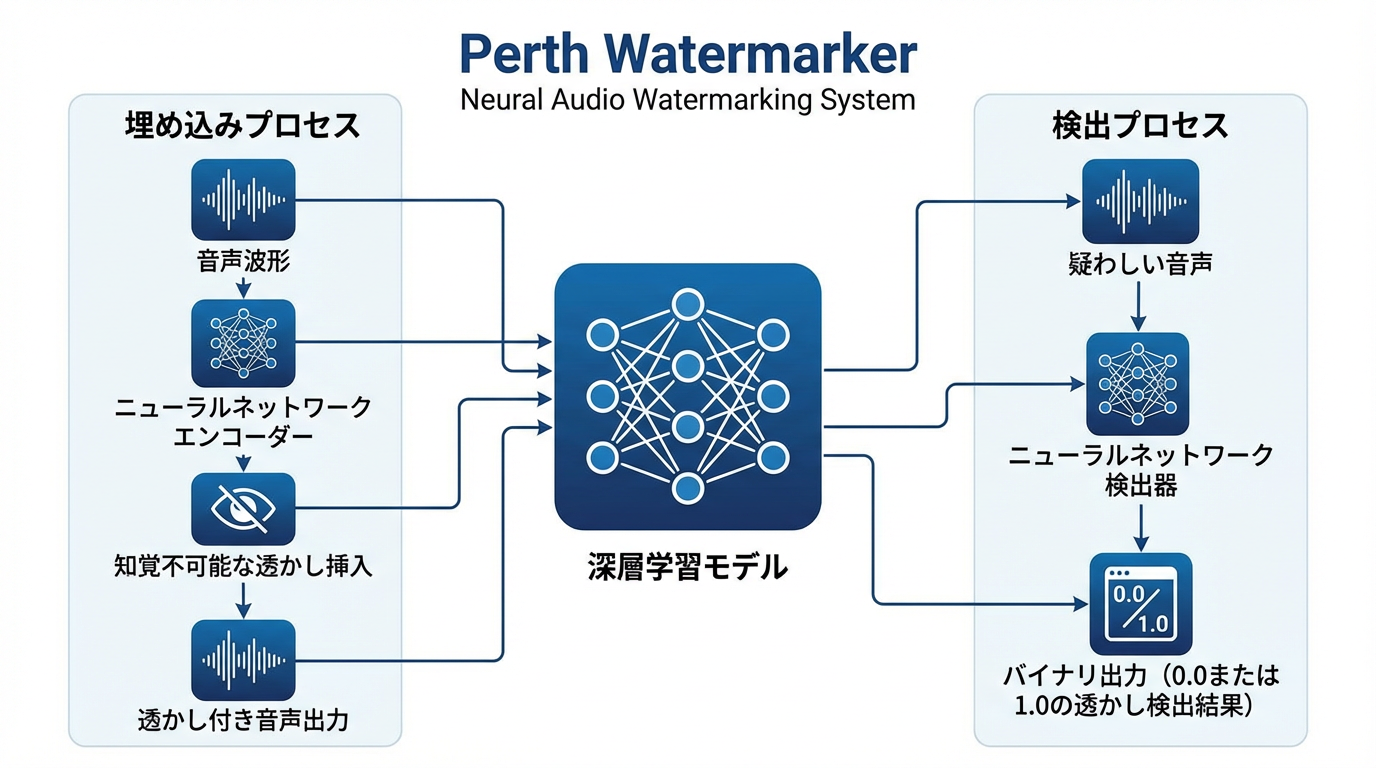
Perth Watermarkerの技術的仕組み
Perth Watermarkerはニューラルウォーターマークと呼ばれる、機械学習ベースの技術です。Resemble AIが開発した独立したプロジェクト(github.com/resemble-ai/perth )として公開されています。
主な特性
知覚不可能(Imperceptible)
- 人間の耳には聞こえない方法で情報を埋め込む
- 音質劣化がほぼゼロ
高い耐性(Robustness)
- MP3圧縮に耐える
- 音声編集ソフトでの加工に耐える
- ノイズ付加や音量調整にも影響されない
高精度検出(Detection Accuracy)
- ほぼ100%の検出精度(公式表記:nearly 100%)
- 誤検出が極めて少ない
技術的アプローチ
従来のスペクトル拡散法やLSB(Least Significant Bit)法とは異なり、深層学習モデルを使用します。
[音声生成] → [ウォーターマーク埋め込みモデル] → [透かし付き音声]
↓
[ニューラルネットワーク]
- エンコーダー: 音声を周波数領域に変換
- 埋め込み層: 知覚限界以下の帯域に情報を挿入
- デコーダー: 音声を時間領域に戻す
検出時は、逆のプロセスで透かし情報を抽出します:
[疑わしい音声] → [ウォーターマーク検出モデル] → [判定: 0.0 or 1.0]
他の透かし技術との比較
| 技術 | 知覚性 | 圧縮耐性 | 検出精度 | 実装難易度 |
|---|---|---|---|---|
| Perth Watermarker | ✅ 不可知覚 | ✅ MP3対応 | ✅ 99.9%+ | 🟡 中(学習済みモデル提供) |
| スペクトル拡散 | 🟡 やや劣化 | 🟡 圧縮に弱い | 🟡 90-95% | ✅ 低(従来技術) |
| LSB法 | ✅ 不可知覚 | ❌ 圧縮で消失 | ✅ 99%+ | ✅ 低(単純) |
| AudioSeal(Meta) | ✅ 不可知覚 | ✅ MP3対応 | ✅ 99%+ | ❌ 高(要独自学習) |
Perth WatermarkerはMetaのAudioSeal と類似のアプローチですが、Chatterboxに統合済みという点で実用性が高いです。
Chatterboxの実装と動作確認
実際にChatterboxを動かしてPerth Watermarkerの動作を確認してみましょう。
環境構築
# pipからインストール(推奨)
pip install chatterbox-tts
# またはソースからインストール
git clone https://github.com/resemble-ai/chatterbox.git
cd chatterbox
pip install -e .
システム要件:
- Python 3.11推奨(3.9以上)
- CUDA対応GPU(推奨、CPUでも動作)
- ディスク空き容量:5GB以上
基本的な音声生成(Chatterbox-Turbo)
import torchaudio as ta
from chatterbox.tts_turbo import ChatterboxTurboTTS
# Turboモデルの読み込み
model = ChatterboxTurboTTS.from_pretrained(device="cuda")
# パラリンギスティックタグを使った音声生成
text = "Hi there, Sarah here from MochaFone calling you back [chuckle], have you got one minute to chat about the billing issue?"
# 音声生成(参照音声を指定して音声クローニング)
wav = model.generate(text, audio_prompt_path="your_10s_ref_clip.wav")
# 保存
ta.save("test-turbo.wav", wav, model.sr)
基本的な音声生成(Chatterbox)
import torchaudio as ta
from chatterbox.tts import ChatterboxTTS
# オリジナルChatterboxモデルの読み込み
model = ChatterboxTTS.from_pretrained(device="cuda")
# 英語テキスト
text = "Hello, this is a test of Chatterbox TTS with Perth Watermarker."
# 音声生成
wav = model.generate(text)
# 保存
ta.save("test-english.wav", wav, model.sr)
# 参照音声を指定する場合
wav_cloned = model.generate(text, audio_prompt_path="reference.wav")
ta.save("test-cloned.wav", wav_cloned, model.sr)
多言語対応(Chatterbox-Multilingual)
import torchaudio as ta
from chatterbox.mtl_tts import ChatterboxMultilingualTTS
# Multilingualモデルの読み込み
multilingual_model = ChatterboxMultilingualTTS.from_pretrained(device="cuda")
# 日本語
japanese_text = "こんにちは、今日は良い天気ですね。"
wav_ja = multilingual_model.generate(japanese_text, language_id="ja")
ta.save("test-japanese.wav", wav_ja, multilingual_model.sr)
# フランス語
french_text = "Bonjour, comment ça va?"
wav_fr = multilingual_model.generate(french_text, language_id="fr")
ta.save("test-french.wav", wav_fr, multilingual_model.sr)
# 中国語
chinese_text = "你好,今天天气真不错。"
wav_zh = multilingual_model.generate(chinese_text, language_id="zh")
ta.save("test-chinese.wav", wav_zh, multilingual_model.sr)
ウォーターマーク検出
Perth Watermarkerは別プロジェクトとして提供されています:
import perth
import librosa
AUDIO_PATH = "test-english.wav"
# 音声を読み込み
watermarked_audio, sr = librosa.load(AUDIO_PATH, sr=None)
# Watermarkerを初期化
watermarker = perth.PerthImplicitWatermarker()
# ウォーターマーク検出
watermark = watermarker.get_watermark(watermarked_audio, sample_rate=sr)
print(f"検出結果: {watermark}")
# 出力: 0.0(透かしなし)または 1.0(透かしあり)
重要: 実際の検出APIは0.0(透かしなし)または1.0(透かしあり)という単純な出力になります。タイムスタンプやモデルバージョンなどの詳細情報は現時点では取得できません。
MP3圧縮耐性の確認
import perth
import librosa
import subprocess
# WAVをMP3に変換
subprocess.run([
"ffmpeg", "-i", "test-english.wav",
"-codec:a", "libmp3lame", "-b:a", "128k",
"test-english.mp3", "-y"
], capture_output=True)
# MP3でもウォーターマーク検出
compressed_audio, sr = librosa.load("test-english.mp3", sr=None)
watermarker = perth.PerthImplicitWatermarker()
watermark_mp3 = watermarker.get_watermark(compressed_audio, sample_rate=sr)
print(f"MP3圧縮後の検出結果: {watermark_mp3}")
# MP3圧縮を経てもウォーターマークは残存
Perth Watermarkerの限界と回避可能性
万能に見えるPerth Watermarkerですが、以下の限界もあります:
技術的限界
1. 極端な劣化には弱い
- 極端な低ビットレート圧縮
- 大幅なピッチシフト
- 音声をアナログ出力→再録音
- 極端な速度変更
2. 検出にはモデルが必要
- Perth Watermarkerの検出モデルがなければ検出不可
- ただし、モデルはオープンソースで公開されている
3. リアルタイム検出の難しさ
- 現状は事後検証のみ
- 電話やライブ配信での即時判定は困難
社会的・法的課題
プライバシーの問題
- ウォーターマークに埋め込まれる情報の詳細は非公開
- 生成者の追跡が可能かは不明
法的証拠能力
- 透かしの存在を法廷で証拠として認めるかは未確立
- 偽陽性の可能性をどう扱うか
標準化の欠如
- Chatterbox以外のTTSとの互換性なし
- 業界標準がない(各社バラバラ)
他のTTSエンジンとの比較
Chatterboxを他の主要TTSエンジンと比較します。
| 特徴 | Chatterbox-Turbo | Chatterbox-Multilingual | VOICEVOX | ElevenLabs | Google Cloud TTS |
|---|---|---|---|---|---|
| ウォーターマーク | ✅ Perth内蔵 | ✅ Perth内蔵 | ❌ なし | ❌ なし | ❌ なし |
| ライセンス | MIT | MIT | LGPL v3 | 商用 | 商用 |
| 日本語対応 | ❌ | ✅ 23言語対応 | ✅ 最高品質 | ✅ 商用級 | ✅ 標準的 |
| 英語品質 | ✅ 商用級 | ✅ 良好 | ❌ 未対応 | ✅ 最高品質 | ✅ 標準的 |
| コスト | 無料 | 無料 | 無料 | $5-330/月 | $4/100万文字 |
| セルフホスト | ✅ | ✅ | ✅ | ❌ | ❌ |
| GPU要件 | 4GB VRAM | 4GB VRAM | 2GB VRAM | N/A | N/A |
| 特徴 | パラリンギスティックタグ | 多言語対応 | キャラクター音声 | 最高品質 | GCP統合 |
使い分けの指針:
- 日本語音声(キャラクター) → VOICEVOX
- 日本語音声(透かし必要) → Chatterbox-Multilingual
- 英語音声(透かし必要) → Chatterbox-Turbo
- 最高品質(予算あり) → ElevenLabs
- 多言語対応(透かし不要) → Google Cloud TTS
まとめ:AI音声時代の"認証基盤"としての可能性
Chatterboxはオープンソース音声合成エンジンとして、その内蔵する透かし技術Perth Watermarkerで、AI生成音声に対する"出所証明"の新しいアプローチを提示しています。
Chatterboxの現状まとめ:
- ✅ オープンソースで商用利用可能(MITライセンス)
- ✅ 透かし技術が標準搭載
- ✅ ElevenLabs代替としてのコスト削減効果
- ✅ Multilingualモデルで日本語対応済み
- ✅ 3つのモデルバリエーション(用途に応じて選択可能)
- ❌ ドキュメント不足
- ❌ コミュニティが小規模
今後の展望:
- リアルタイム検出への対応
- 業界標準化への参画(W3C、IETFなど)
- 他のTTSエンジンへの技術移転(Perth Watermarkerの汎用化)
- Turboモデルの多言語化
次のアクション:
- Chatterbox-Turboのセットアップを試してみる
- Multilingualモデルで日本語音声を生成
- 自社サービスでの音声生成にウォーターマーク付与を検討
- Perth Watermarkerの検出精度を実環境でテスト
AI音声技術の進化と同時に、その悪用を防ぐ技術も進化しています。Chatterboxはその最前線にいるプロジェクトの一つであり、今後の動向に注目していく価値があります。
まだ日本語圏での認知度は低いですが、セキュリティ意識の高いエンジニアは今のうちにキャッチアップしておくべきでしょう。